Hello all!
I have the pleasure to attend Akademy this year again. From my past experience, I’m really looking forward to have a good time again. Lots of hacking, meeting known and unknown faces, drinking beer and socializing ahead! I also love that it’s in a (to me) new country again, and wonder what I will see of the Czech Republic and Brno!
This year, the conference schedule is a bit different from the past years. Not only do we have the usual two days packed with interesting talks and keynotes. No - this year there will also be workshops on the third day! These are more in-depth talks which hopefully teach the audience some new skills, be it QML, mobile development, testing, or … profiling :) Your’s truly has the honor to hold a one-hour Profiling 101 workshop.
continue reading...
Hello everyone,
with a tingly feeling in my belly, I’m happy to announce heaptrack, a heap memory profiler for Linux. Over the last couple of months I’ve worked on this new tool in my free time. What started as a “what if” experiment quickly became such a promising tool that I couldn’t stop working on it, at the cost of neglecting my physics masters thesis (who needs that anyways, eh?). In the following, I’ll show you how to use this tool, and why you should start using it.
A faster Massif?
Massif, from the Valgrind suite, is an invaluable tool for me. Paired with my Massif-Visualizer, I found and fixed many problems in applications that lead to excessive heap memory consumption. There are some issues with Massif though:
- It is relatively slow. Especially on multi-threaded applications the overhead is large, as Valgrind serializes the code execution. In the end, this sometimes prevents one from using Massif altogether, as running an application for hours is unpractical. I know that we at KDAB sometimes had to resort to over-night or even over-weekend Massif sessions in the hope to analyze elusive heap memory consumption issues.
- It is not easy to use. Sure, running
valgrind --tool=massif <your app> is simple, but most of the time, the resulting data will be too coarse. Frequently, one has to play around to find the correct parameters to pass to --depth, --detailed-freq and --max-snapshots. Paired with the above, this is cumbersome. Oh and don’t forget to pass --smc-check=all-non-file when your application uses a JIT engine internally. Forget that, and your Massif session will abort eventually. - The output is only written at the end. When you try to debug an issue that takes a long time to show up, it would be useful to regularly inspect the current Massif data. Maybe the problem is already apparent and we can stop the debug session? With Massif, this is not an option, as it only writes the output data at the end, when the debugee stops.
continue reading...
Hello everyone!
Finally I take some time to blog again. I’m currently in Vienna for the joint KDevelop/Kate sprint together with lots of other hackers. Many thanks to Joseph for planning and partially financing this sprint! And of course as usual many thanks to the KDE e.V. and all the donors for bringing in the rest of the money required to pull something like this off!
Anyhow, considering that the sprint is running since Tuesday, I need to catch up quite a bit… Actually, I have to start even before that since I committed something quite noteworthy in KDevelop and KMail last week.
Reducing Memory Consumption
KMail
Shared Data References
I attended the recent Akonadi sprint that took place at the KDAB office in Berlin (where I work btw.). I heard that Alex Fiestas would come and show us his memory problems in KMail, which sooner or later was eating multiple GBs of memory for him. That sounded like a fun task to improve, fixing performance issues is what I love to do :) So I investigated it with Valgrind/Massif and my pmap script. After quite some time I came up with a patch to fix the memory increase, which is waiting for Stephen Kelly to review. It should be merged into master very soon™.
continue reading...
As I just wrote in another article, Massif is an invaluable tool. The [Visualizer](https://projects.kde.org/massif-visualizer] I wrote is well appreciated and widely used as far as I can see.
A few days ago though, I did a very long (~16h) Massif run on an application, which resulted in a 204MB massif.out data file. This proved to be a very good stress test for my visualizer, which triggered me to spent some time on optimizing it. The results are pretty nice I thing, so look forward to Massif-Visualizer 0.4:
Reduced Memory Consumption
Yeah, meta eh? Just how I like it! I’ve used Massif to improve the memory consumption of Massif-Visualizer, and analyzed the data in the Visualizer of course… :)
Initial Version
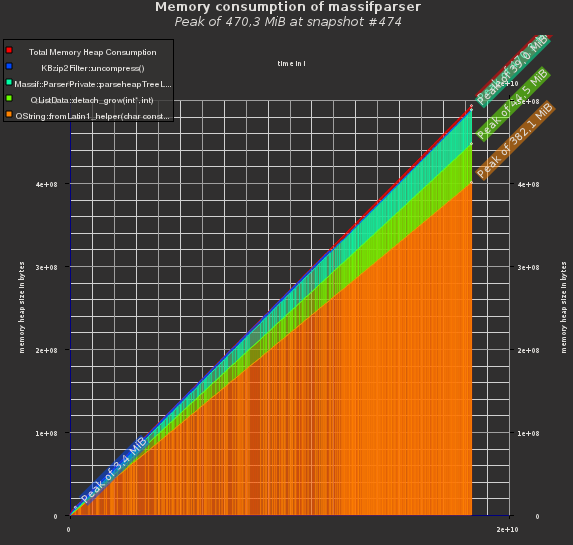
fig. 1: initial memory consumption of the visualizer
continue reading...
Hey all!
I’m happy to announce the release of Massif-Visualizer 0.3. You can download the sources here:
http://download.kde.org/download.php?url=stable/massif-visualizer/0.3/src
Highlights of this release:
- translations into 18 different languages
- basic support for hiding of functions via context menu
- basic support for custom allocators
- configurable precision of memory consumption display
- various optimizations, bug fixes and other improvements. take a look at the changelog for more information
Future Development
It took me much too long to get this release out and hope to do better in the future. Current git master already contains some new patches - try it out! I especially like the improved display of the callgraph which now aggregates the tails of the callgraph tree, i.e. the end of the backtrace which mostly starts main() etc.
continue reading...
Hey all!
I’m happy to release Massif Visualizer v0.2. This is mainly a “fix the build-system” release, no new features have been added.
You can download it here: http://kde-apps.org/content/show.php?content=122409
Mac Support
Thanks to the reports by Chris Jones it’s now possible to build and use Massif Visualizer on Max OS X, see e.g.:
http://www.hep.phy.cam.ac.uk/~jonesc/massif-visualizer-OSX-1.png
http://www.hep.phy.cam.ac.uk/~jonesc/massif-visualizer-OSX-2.png
He has also submitted the portsfile for inclusion in Macports: https://trac.macports.org/ticket/27168
KGraphViewer now optional
I’ve made the KGraphViewer dependency optional, if anyone does not want it (even though this removes like 50% of the tools features).
KDE Infrastructure
I’ve also prepared the steps for moving Massif-Visualizer into KDE Extragear and asked kde-devel for review. I already use the KDE infrastructure now:
Website:
<https://projects.kde.org/projects/playground/sdk/massif-visualizer> Git:
continue reading...
Good news everyone!
Since Gaël finally came around to release KGraphViewer 2.1, I can go ahead and do the same for Massif Visualizer!
Download Massif Visualizer 0.1
This is the first release and I would be very happy if more users gave me their feedback. I intend to move to git.kde.org soon in order to leverage the KDE infrastructure (mostly translations, bug tracker, releases)… This also means: There are no translations yet! I also intend to update my OBS repository to provide packages for the first release.
Stay tuned for updates.
continue reading...
Just a quick status update: Massif Visualizer now reacts on user input. Meaning: You can click on the graph and the corresponding item in the treeview gets selected and vice versa. It’s a bit buggy since KDChart is not reliable on what it reports, but it works quite well already.
Furthermore the colors should be better now, peaks are labeled (better readable on bright color schemes, I’m afraid to say…), legend is shown, …
Now lets see how I can make the treeview more useful!
continue reading...
memory consumption overview
Hello everyone!
In my opinion, the massif visualizer is ready for testing. I bet there are still a few rough edges, but the most important features are in. So if you are going to do any memory profiling these days, please take a look at my tool and give me feedback. I’d be especially interested in whether the massif visualizer helps in the work flow to analyze massif data files.
My personal work flow so far is the following:
callgraph of detailed massif snapshot
- generate massif log, one way or the other (unit tests preferred since they give you reproducible test cases)
- open log in massif-visualizer, look at overall consumption chart 1. how does the memory consumption evolve? is there a memleak? 2. are there designated peaks which could be reduced? 3. are there any (significant) contributions to the memory consumption, that needlessly stay over the whole application life?
- to find the actual culprits in code and/or to grasp the composition of a memory peak, use the detailed snapshot analysis
continue reading...


{kind=link}
{kind=link}