Improving Massif-Visualizer For Large Data Files
As I just wrote in another article, Massif is an invaluable tool. The [Visualizer](https://projects.kde.org/massif-visualizer] I wrote is well appreciated and widely used as far as I can see.
A few days ago though, I did a very long (~16h) Massif run on an application, which resulted in a 204MB massif.out data file. This proved to be a very good stress test for my visualizer, which triggered me to spent some time on optimizing it. The results are pretty nice I thing, so look forward to Massif-Visualizer 0.4:
Reduced Memory Consumption
Yeah, meta eh? Just how I like it! I’ve used Massif to improve the memory consumption of Massif-Visualizer, and analyzed the data in the Visualizer of course… :)
Initial Version
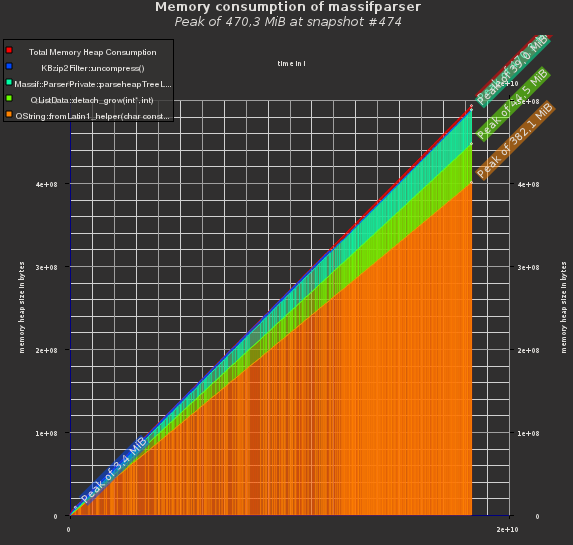
fig. 1: initial memory consumption of the visualizer
The initial version of my visualizer took about ~470MB of memory to load the 204MB data file above. 80% of that was required for QString allocations in the callgraph of each detailed snapshot, i.e. the function signatures and location. See fig. 1 for the details.
QString to QByteArray
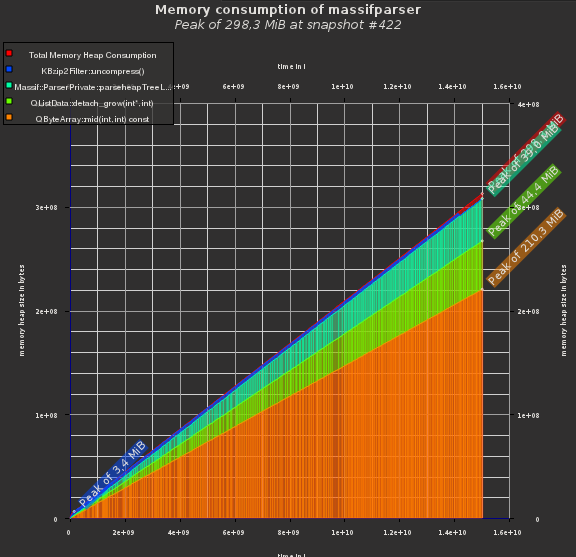
fig. 2: QByteArray instead of QString: 50% less memory
Thomas McGuire gave me the tip of using QByteArray instead, since the Massif callgraph data is just ASCII data. We can convert the data to QString where required, essentially saving us 50% of the memory consumption. You can see that applied in fig. 2. It was simple to code and already reduced the memory consumption considerably.
Implicit Sharing
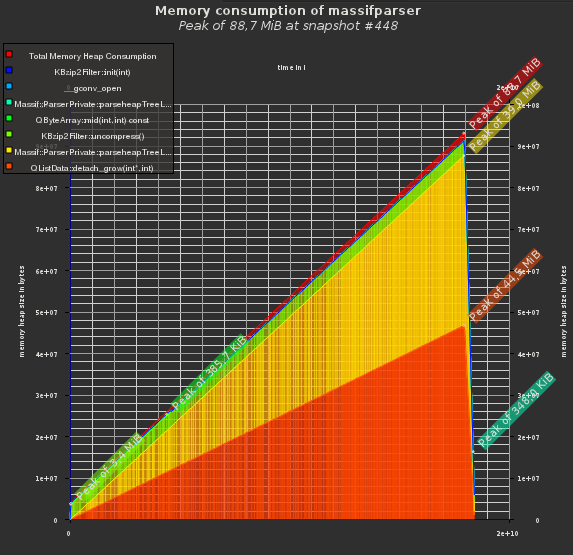
fig. 3: leveraging implicit sharing
I committed the above, thinking this was it. But thanks to the awesome people in the KDE community, this time André Wöbbeking, I was thankfully shown wrong: He commented on my commit, arguing that I should try out to leverage the implicit sharing of Qt containers, such as QByteArray. After all, the strings we have here are function signatures and file locations, which are repeated quite often. Especially when you have recursion in your call tree, or the same functions are encountered again and again in Massif snapshots, you can potentially safe a lot of memory by leveraging implicit sharing.
Personally, I’m suprised to see just how much this gains in this case! See fig 3., where the string allocations are nearly gone completely from the Massif log! Now only the tree node allocations, and the containers saving them, are visible in the memory log - something I do not plan to reduce further.
If you are interested in how this was implemented, take a look at commit 4be5dad13fb.
Final Notes
I think this shows quite nicely how to improve the memory consumption of an application. If you want to verify my results, I’ve uploaded the massif log files. Remember that you can open compressed files seamlessly in Massif-Visualizer. The massif.out.data.bz2 file contains the test-data of the 16h Massif run.
You should probably use the latest Massif-Visualizer code though, since I’ve also optimized the performance of it considerably compared to the last released version 0.3. Furthermore, data files are now loaded in the background, showing a nice progress bar while doing that. If you open the big data file in 0.3 you’ll notice why I decided to optimize the visualizer :)
An interesting thing to note btw. is that the callgrind data format compresses files and function signatures, yielding much smaller data files and reducing the KCacheGrind’s memory consumption, esp. since it will automagically leverage the implicit sharing of Qt’s string classes.
Now it is probably time to stop slacking and start work-work again :) I do have quite a few ideas more for the next Massif-Visualizer though, especially an export functionality for the graphs is high on my TODO list!
Comments
Want to comment? Send me an email!
Comment by Anonymity is great (not verified) (2012-03-19 14:20:00)
Thanks for the tips. I wonder what’s the difference between QLatin1String and QByteArray. Why is QByteArray better than QLatin1String?
Comment by Milian Wolff (2012-03-19 19:45:00)
QLatin1Stringis not supposed to used for data parsed from files, but rather for compile-time constants. One big issue would be that the string data is never freed (just take a look at the class - it doesn’t even have a dtor!).