Hey all,
do you know this: You work on something locally in git, ensure everything compiles and the tests pass, then commit and hit git push.What could possibly go wrong at that point, eh? Well, far too often I forgot to git add some new source file. Best-case I’ll notice this directly, worst-case I’ll see my CI complaining. But, like yesterday in kdev-clang, I might be afk at that point and someone else will have to revert my change and I’ll have to fix it up the day after, polluting the git history while at it…
Thanks to some simple shell scripting and the powerful git hook architecture, it is pretty simple to protect oneself against such issues:
#!/bin/sh
#
# A hook script to verify that a push is not done with untracked source file
#
# To use it, either symlink this script to $your-git-clone/.git/hooks/pre-push
# or include it in your existing pre-push script.
#
# Perl-style regular expression which limits the files we interpret as source files.
# The default pattern here excludes CMakeLists.txt files and any .h/.cpp/.cmake files.
# Extend/adapt this to your needs. Alternatively, set the pattern in your repo via:
# git config hooks.prepush.sourcepattern "$your-pattern"
pattern=$(git config --get hooks.prepush.sourcepattern)
if [ -z "$pattern" ]; then
pattern="(?:(?:^|/)CMakeLists\.txt|\.h|\.cpp|\.cmake)$"
fi
files=$(git status -u --porcelain --no-column | sed "s/^?? //" | grep -P "$pattern")
if [ -z "$files" ]; then
exit 0
fi
echo
echo "ERROR: Preventing push with untracked source files:"
echo
echo "$files" | sed "s/^/ /"
echo
echo "Either include these files in your commits, add them to .gitignore"
echo "or stash them with git stash -u."
echo
exit 1
continue reading...
NOTE: find most recent version on github: https://github.com/milianw/shell-helpers/blob/master/clipboard
Here’s a little script you can save in your path and do things like
# paste current clipboard into file
clipboard > "some_file"
# copy some file into clipboard
cat "some_file" | clipboard
Actually I find it rather useful so I thought I should share it.
#!/bin/bash
# Access your KDE 4 klipper on the command line
# usage:
# ./clipboard
# will output current contents of klipper
# echo "foobar" | ./clipboard
# will put "foobar" into your clipboard/klipper
# check for stdin
if ! tty -s && stdin=$(</dev/stdin) && [[ "$stdin" ]]; then
# get the rest of stdin
stdin=$stdin$'\n'$(cat)
# oh, nice - user input! we set that as current
# clipboard content
qdbus org.kde.klipper /klipper setClipboardContents "$stdin"
exit
fi
# if we reach this point no user input was given and we
# print out the current contents of the clipboard
qdbus org.kde.klipper /klipper getClipboardContents
continue reading...
Massif is a really nifty tool which is very powerful, especially paired with my visualizer. The caveat of course is that it slows down the application considerably, I’ve seen anything up to a factor of 100… I see no alternative to Massif when it comes to investigating where your memory problems come from. But if you just want to see whether you have a problem at all, tracking the total memory consumption should suffice.
A few days ago, I came across pmap on Stack Overflow, which makes it easy to track the RSS memory consumption of an application using the -x switch. Of course I had to write some bash magic to automate this process and visualize the data using Gnuplot! Behold:
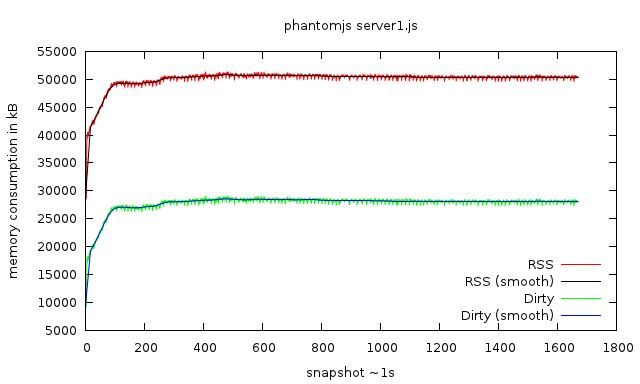
memory consumption of a PhantomJS script over ~30min
continue reading...
I’ve had a major annoyance today: The plot generated by gnuplot looked good inside the wxt terminal but I simply couldn’t get a proper fullsized DIN A4 postscript exported. This is how I’ve done it now:
- Inside gnuplot:
```bash
set size ratio 0.71 # this is the ratio of a DIN A4 page (21/29.7)
set terminal postscript enhanced landscape "Arial" 9 # you can change landscape to portrait and the fontname and -size
set output 'yourfilename.ps' # this is your export file
replot # or put your custom plot command here ```
- In a shell:
```bash
ps2ps -sPAGESIZE=a4 yourfilename.ps new_dina4_file.ps ```
- Now you can simply print
new_dina4_file.ps from within KGhostView for example. Have fun!
continue reading...
Unit tests are in my eyes a very important part of programming. KDE uses them, KDevelop does - the PHP plugin I help writing does as well. cmake comes with a ctest program which does quite well to give you a quick glance on which test suite you just broke with your new fance feature :)
But I am very dissatisfied with it. Right now I usually do the following
# lets assume I'm in the source directory
cb && ctest
# look for failed test suites
cd $failed_test_suite_path
./$failed_test_suite.shell | less
# search for FAIL
cs
cd $to_whereever_I_was_before
That’s pretty much for just running a test. Especially all that cding and lessing became very tedious. Tedious is good, because I eventually fix it:
introducing kdetest
I wrote a bash function (with autocompletion!!!) called kdetest. Calling it without any parameter will run all test suites and gives a nice report of failed functions at the end. Here’s an example (run via cs php && kdetest).
continue reading...
Yes, I am a Linux user and I really appreciate the freedom I get by using either an awesome desktop environment or the command line - or both!
The function I’m going to present you gives you a good overview of how many words, lines and bytes files in a given folder have. I’m speaking about wc.
The bash script I wrote applies wc to every web file in a folder and every sub folder. Web files are:
*.php*.html / *.htm*.tpl*.sql*.js*.css.htaccess- files without an extension (e.g.
README)
Furthermore you can exclude folders by using the -e parameter. I needed that feature to exclude scripts which are not written by me (see below). But because of that I have had to commit a sin: using eval…
Recursive wc
#!/bin/bash
# usage
# -s = search path
# -e = excluded paths
# examples:
# current folder: ./wc.sh
# other folder: ./wc.sh -s ../foobar/
# exclude folder: ./wc.sh -e "*/foobar/*"
# exclude folder: ./wc.sh -e "*/folder1/*" -e "*/folder2/*"
# default params
SEARCH_PATH="./"
EXCLUDE=""
# read command line params
while getopts "s:e:" PARAM
do
case "${PARAM}" in
s) SEARCH_PATH="$OPTARG";;
e) EXCLUDE=$EXCLUDE" -not -path \"$OPTARG\"";;
esac
done
if [ "$EXCLUDE" = "" ]
then
find $SEARCH_PATH \
-regextype posix-egrep \
-type f \
-regex ".*(\.(php|html?|tpl|css|sql|js))$" \
-or -name ".htaccess" \
| xargs wc
else
# evil eval
eval 'find $SEARCH_PATH \
-regextype posix-egrep \
-type f \
\( -regex ".*(\.(php|html|tpl|css|sql|js))$" \
-or -name ".htaccess" \)\
'$EXCLUDE' \
| xargs wc'
fi
continue reading...
Everyone who uses the command line regularly has a bunch of (at least for him) useful helper scripts. I now took the liberty to put mine on github for general consumption.
You can find them at: http://github.com/milianw/shell-helpers/tree/master
Some of these might be more useful than others, you decide :) Personally, I can’t live without the following:
apupgrade
a shortcut to update your Debian system with one command - no questions asked `openurl`
opens a given URL in an already opened browser instance or starts a new browser session. Not only one browser is checked. I use it because firefox is slow to start and konqueror is blazingly fast to start. But when firefox is already open I want to use that. `xerr`
shortcut for fast error checking in your Xorg log `clipboard`
makes KDE4 Klipper contents available on the CLI (read _and_ write access!) `debug`
shortcut to start a GDB session: debug APP APP_ARGS is all you have to do. Its basically the same as doing:
continue reading...
After a long period of silence I present you the following bash script for downloading books from http://springerlink.com. This is not a way to circumvent their login mechanisms, you will need proper rights to download books. But many students in Germany get free access to those ebooks via their universities. I for example study at the FU Berlin and put the script in my Zedat home folder and start the download process via SSH from home. Afterwards I download the tarball to my home system.
Read on for the script.
Download the script (attached below), push it to your Zedat account, make it executable and run it. You’ll have to give it a link to a book-detail page like this one for example. Also take a look at the example call at the top of the script.
Requires bash, wget, iconv, egrep.
Note: Take a look at the comments, Faro has come up with an updated Bash script which properly handles ebooks which span multiple pages on SpringerLink and merges the pdf-files with pdftk. Thanks Faro!
continue reading...
UPDATE : Also check out mp3dump part 2
On some undefined occasion you might want to dump the audio stream of a flash file. This is how you do it:
- Get the
*.flv, e.g. visit youtube with Konqueror and check /tmp for a file like FlashV5SQLt - this is your FLV. - Install some dependencies:
ffmpeg is required, mp3info and ecasound are optional but strongly recommended. - Download the script below (it’s attached!) and save it inside your
$PATH, remember how you’ve called it! - I’ve saved the script inside
~/.bin which is inside my $PATH so all I have to do now is running it:
mp3dump FlashV5SQLt "Foo Bar" "All Your Base Are Belong To Us"
This would rip the audio stream of FlashV5SQLt to a file named Foo Bar - All Your Base Are Belong To Us.mp3 - with emulated stereo sound and basic MP3 tags (artist and title). Coolio!
So what does this neat-o-bash-magic look like?
Note: The script is attached below, so no copy’n’paste is required (but optionally supported :-) )
#!/bin/bash
#
# Simple script to rip the audio stream of a FLV to MP3
#
# usage: mp3dump INPUT.flv ARTIST TITLE
# example: mp3dump FlashhxSjv3 "Foo Bar" "All your Base are Belong to Us"
# Author: Milian Wolff
# depends on: ffmpeg
# optional: ecasound for stereo sound emulation
# optional: mp3info to write title and artist mp3 tags
if [[ "$(which ffmpeg)" == "" ]]; then
echo -e "\033[41mInstall ffmpeg or this script wont work!\033[0m"
exit
fi
if [[ "$1" == "" || "$2" == "" || "$3" == "" || "$4" != "" ]]; then
echo "Usage: $(basename $0) INPUT.flv ARTIST TITLE"
exit
fi
dest="$2 - $3.mp3"
tmpfile="/tmp/$$-$dest"
echo "Destination file is: $dest"
echo
echo
echo "generating mp3 file..."
echo
ffmpeg -i "$1" -f mp3 -vn -acodec copy "$dest" 1>/dev/null
echo
echo -e " \033[32mdone\033[0m"
echo
if [[ "$(which ecasound)" == "" ]]; then
echo "You can optionally install ecasound to simulate stereo sound"
echo
else
echo -n "simulating stereo sound..."
ecasound -d:1 -X -i "$dest" -etf:8 -o "$tmpfile" 1>/dev/null
mv "$tmpfile" "$dest"
echo -e " \033[32mdone\033[0m"
echo
fi
if [[ "$(which mp3info)" == "" ]]; then
echo "You can optionally install mp3info to write basic mp3 tags automatically"
echo
else
echo -n "writing basic mp3 tags..."
mp3info -a "$2" -t "$3" "$dest"
echo -e " \033[32mdone\033[0m"
echo
fi
echo "Have fun with »$dest«"
continue reading...
So just yesterday I’ve published a bash script which rips the audio stream of Flash Videos (*.flv) to mp3 format. It’s nice, fast and imo all-purpose. But I didn’t like the audio quality. Thus below you can find a second version of the script which is using mplayer and lame instead of ffmpeg. Usage and behaviour should be pretty much the same. Only the audio quality should be better on cost of a bit more computing.
Since it relies on the fact that the input *.flv video already uses MP3 encoding for its audio stream this might not work for every flash file! Youtube works just fine though. You can find the script after the break, it’s also attached below. For usage / installation / more information read the old article.
If you wonder why I reencode the audiodump with lame: The dumped mp3 file is considered by most (all?) audio players to be ~10x the length. A five minute video gets a 45 minute audio dumpfile. It plays fine but seeking is a mess. Reencoding fixes this. If you know an alternative which does not require reencoding or is generally faster - please drop a comment!
continue reading...