Hey all,
do you know this: You work on something locally in git, ensure everything compiles and the tests pass, then commit and hit git push.What could possibly go wrong at that point, eh? Well, far too often I forgot to git add some new source file. Best-case I’ll notice this directly, worst-case I’ll see my CI complaining. But, like yesterday in kdev-clang, I might be afk at that point and someone else will have to revert my change and I’ll have to fix it up the day after, polluting the git history while at it…
Thanks to some simple shell scripting and the powerful git hook architecture, it is pretty simple to protect oneself against such issues:
#!/bin/sh
#
# A hook script to verify that a push is not done with untracked source file
#
# To use it, either symlink this script to $your-git-clone/.git/hooks/pre-push
# or include it in your existing pre-push script.
#
# Perl-style regular expression which limits the files we interpret as source files.
# The default pattern here excludes CMakeLists.txt files and any .h/.cpp/.cmake files.
# Extend/adapt this to your needs. Alternatively, set the pattern in your repo via:
# git config hooks.prepush.sourcepattern "$your-pattern"
pattern=$(git config --get hooks.prepush.sourcepattern)
if [ -z "$pattern" ]; then
pattern="(?:(?:^|/)CMakeLists\.txt|\.h|\.cpp|\.cmake)$"
fi
files=$(git status -u --porcelain --no-column | sed "s/^?? //" | grep -P "$pattern")
if [ -z "$files" ]; then
exit 0
fi
echo
echo "ERROR: Preventing push with untracked source files:"
echo
echo "$files" | sed "s/^/ /"
echo
echo "Either include these files in your commits, add them to .gitignore"
echo "or stash them with git stash -u."
echo
exit 1
continue reading...
Hey all,
I recently needed to generate values following a Maxwell distribution. Wikipedia gives the hint that this is a Gamma distribution, which in C++11 is easily useable. Thus, thanks to <random>, we can setup a Maxwell distribution in a few lines of code:
#include <random>
#include <chrono>
#include <iostream>
using namespace std;
int main()
{
unsigned seed = chrono::system_clock::now().time_since_epoch().count();
default_random_engine generator(seed);
// Boltzmann factor times temperature
const double k_T = 0.1;
// setup the Maxwell distribution, i.e. gamma distribution with alpha = 3/2
gamma_distribution<double> maxwell(3./2., k_T);
// generate Maxwell-distributed values
for (int i = 0; i < 10000; ++i) {
cout << maxwell(generator) << endl;
}
return 0;
}
Pretty neat, I have to say!
continue reading...
The default output of Apaches Options +Indexes doesn’t look good at all. Very 1990 something… But - as with pretty much any open source open source software - there are tons of options, which enable you to change everything to your likings!
The contents of .htaccess
# default order: descending by name
IndexOrderDefault Descending Name
# set the following options:
# - ignore case
# - don't display the description column
# - display folders first
# - set the width of the name column to 40 chars
# - don't display the default HTML output (doctype, head, ..., starting <body> tag)
# - use Fancy Indexing
# - set IconHeight und Width to 16 pixels (FamFams Icons use these dimensions)
IndexOptions +IgnoreCase +SuppressDescription +FoldersFirst +NameWidth=40 +SuppressHTMLPreamble +FancyIndexing +IconHeight=16 +IconWidth=16
# we want to use indexes for this folder!
Options +Indexes
# the header template, which is displayed before the list
HeaderName ../list_header.html
# the footer template, which is displayed after the list
ReadmeName ../list_footer.html
# don't display the link to the root folder
IndexIgnore ..
# set the default icon to a fancy famfam icon
DefaultIcon ../images/bricks.png
continue reading...
For those who use nano as their CLI editor of choice: Here’s a syntax highlighting file for Git commit messages which also supports the special KDE commit hook keywords.
## syntax highlighting for git commit messages of KDE projects
syntax "patch" ".git/COMMIT_EDITMSG$"
# overlong lines
color brightred "^.{70,}.+$"
# KDE commit hook keywords, see: http://community.kde.org/Sysadmin/GitKdeOrgManual#Commit_hook_keywords
color yellow "^(FEATURE|BUG|CCBUG|FIXED-IN|CCMAIL|REVIEW|GUI|DIGEST):.*$"
color yellow "(SVN_SILENT|GIT_SILENT|SVN_MERGE)"
# comment
color blue "^#.*$"
# special comment lines
color green "^# Changes to be committed:"
color red "^# Changes not staged for commit:"
color brightblue "^# Untracked files:"
color brightblue "^# On branch .+$"
color brightblue "^# Your branch is ahead of .+$"
# diff files
# meh - cannot match against \t ... should be: ^#\t.*$
color cyan "^#[^ a-zA-Z0-9][^ ].*$"
continue reading...
NOTE: find most recent version on github: https://github.com/milianw/shell-helpers/blob/master/clipboard
Here’s a little script you can save in your path and do things like
# paste current clipboard into file
clipboard > "some_file"
# copy some file into clipboard
cat "some_file" | clipboard
Actually I find it rather useful so I thought I should share it.
#!/bin/bash
# Access your KDE 4 klipper on the command line
# usage:
# ./clipboard
# will output current contents of klipper
# echo "foobar" | ./clipboard
# will put "foobar" into your clipboard/klipper
# check for stdin
if ! tty -s && stdin=$(</dev/stdin) && [[ "$stdin" ]]; then
# get the rest of stdin
stdin=$stdin$'\n'$(cat)
# oh, nice - user input! we set that as current
# clipboard content
qdbus org.kde.klipper /klipper setClipboardContents "$stdin"
exit
fi
# if we reach this point no user input was given and we
# print out the current contents of the clipboard
qdbus org.kde.klipper /klipper getClipboardContents
continue reading...
Massif is a really nifty tool which is very powerful, especially paired with my visualizer. The caveat of course is that it slows down the application considerably, I’ve seen anything up to a factor of 100… I see no alternative to Massif when it comes to investigating where your memory problems come from. But if you just want to see whether you have a problem at all, tracking the total memory consumption should suffice.
A few days ago, I came across pmap on Stack Overflow, which makes it easy to track the RSS memory consumption of an application using the -x switch. Of course I had to write some bash magic to automate this process and visualize the data using Gnuplot! Behold:
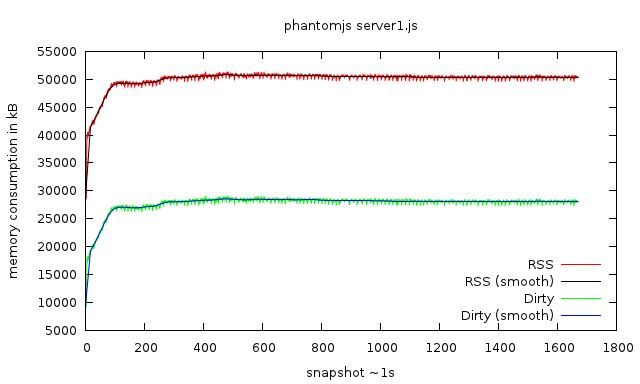
memory consumption of a PhantomJS script over ~30min
continue reading...
Let’s assume you want to display the logo of your company in your Qt app. Most probably that logo has just single color with an alpha channel.But: Having the color hard coded in the image is not nice, there are users (like me!) out there, who use a custom (dark!) color scheme. Meaning: If your logo is black/dark and assumes a bright background and you just embed it blindly in your app, I probably won’t see it since the background will be dark in my case.
Here is a solution for the simple case of a mono-colored PNG with an alpha channel which I came up with:
QLabel* label = new QLabel;
// load your image
QImage img(QString("..."));
// morph it into a grayscale image
img = img.alphaChannel();
// the new color we want the logo to have
QColor foreground = label->palette().foreground().color();
// now replace the colors in the image
for(int i = 0; i < img.colorCount(); ++i) {
foreground.setAlpha(qGray(img.color(i)));
img.setColor(i, foreground.rgba());
}
// display the new logo
label->setPixmap(QPixmap::fromImage(img));
label->show();
continue reading...
Use the snippet below in your ~/.nanorc or /etc/nanorc file to highlight *.ini files like php.ini in Nano.
# ini highlighting
syntax "ini" "\.ini(\.old|~)?$"
# values
color brightred "=.*$"
# equal sign
color green "="
# numbers
color brightblue "-?[0-9\.]+\s*($|;)"
# ON/OFF
color brightmagenta "ON|OFF|On|Off|on|off\s*($|;)"
# sections
color brightcyan "^\s*\[.*\]"
# keys
color cyan "^\s*[a-zA-Z0-9_\.]+"
# comments
color brightyellow ";.*$"
continue reading...
NOTE: This script is apparently against the licensing contract between universities and Springer, see: http://www.bib.hm.edu/aktuelles/news/newsdetail_9984.de.html
NOTE 2: I do not maintain this script anymore. Please look for an alternative.
Seems like quite some people are interested in my bash script for downloading ebooks from http://springerlink.com.
That script has some quirks, the greatest of all that it was written in bash which makes it kind of hard to implement new features. And one which was requested was support for books which span multiple pages on SpringerLink.
So here I present springer_download.py - a Python rewrite which should handle all the old links and some more. This is the very first program I’ve written in Python. And since it has to run on the Zedat servers it’s limited to Python 2.4.x without any fancy shmancy additions (a pity, since I’d love to use urlgrabber or pycurl).
continue reading...
Unit tests are in my eyes a very important part of programming. KDE uses them, KDevelop does - the PHP plugin I help writing does as well. cmake comes with a ctest program which does quite well to give you a quick glance on which test suite you just broke with your new fance feature :)
But I am very dissatisfied with it. Right now I usually do the following
# lets assume I'm in the source directory
cb && ctest
# look for failed test suites
cd $failed_test_suite_path
./$failed_test_suite.shell | less
# search for FAIL
cs
cd $to_whereever_I_was_before
That’s pretty much for just running a test. Especially all that cding and lessing became very tedious. Tedious is good, because I eventually fix it:
introducing kdetest
I wrote a bash function (with autocompletion!!!) called kdetest. Calling it without any parameter will run all test suites and gives a nice report of failed functions at the end. Here’s an example (run via cs php && kdetest).
continue reading...